自信息大爆炸以来,如何建立一个高效的个人信息获取方式,成为了一个永恒的话题。尽管个性化信息流在很大程度上解决了普通用户满足碎片化资讯的需求,但对于许多老网民以及对信息质量有要求的人来说,今日头条和 Google Feed 这样的产品并不总是能满足我们的需求。
究其原因,是因为上一代个性化信息流是基于用户行为的滤波协同算法推荐,它往往并不针对内容本身的质量做出判断,而是依据与你行为相似的其他用户对内容的喜好程度进行推荐。愿意消费高质量内容的用户在高日活型 App 中总是少数,这就导致了推荐算法类资讯产品无法满足这部分用户的需求。
这也是很多人在个性化信息时代,仍然使用 RSS 来阅读的原因之一。
然而,RSS 阅读本身也有很大的问题,尤其是在中文互联网上,优质内容往往混杂在综合性信息流之中。比如,如果你关注商业、财经与互联网行业,你可能很难把那些优秀创作者的个人公众号订阅全(因为可能有上百个),并且他们的更新频度都很低。
因此,更理性的选择是,你直接订阅虎嗅或者钛媒体这样仍然雇佣传统编辑,以类似传统编辑部的机制对信息进行一轮筛选的大聚合器。但这样的大聚合器,迫于商业化的生计压力,每天要在其信息流中放入上百篇以上的文章,其中不乏一些是标题党和广告软文。而其中不是广告的那些,也不一定是我们所关心的话题。
长此以往,我们虽然用 RSS 阅读器解决了被平台和算法摆布的命运,但实际上我们回到了信息处理的原始时代,每天被 RSS 阅读器中上万的未读影响心情。
那么,就止步于此了吗?
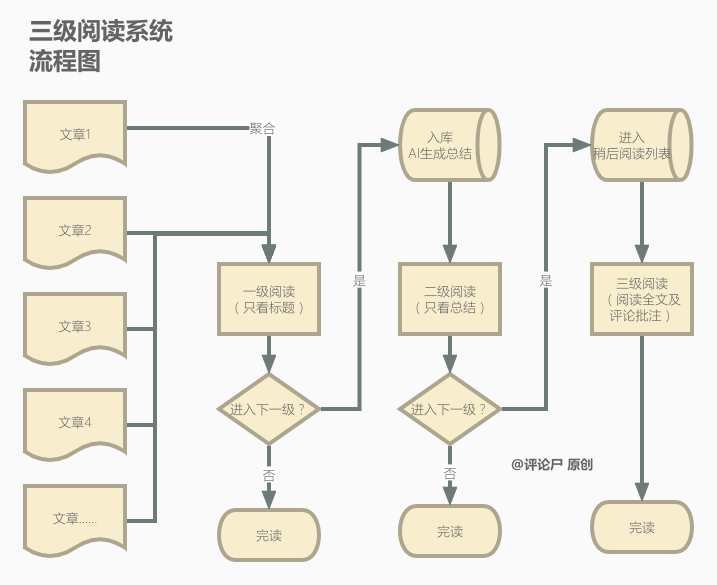
在之前,似乎确实如此,但现在有了 ChatGPT 类大语言模型的帮助,我们可以建立一套私人的三级阅读系统,它的核心是将我们的阅读行为分为三个等级:
一级阅读:只看标题;
二级阅读:只看摘要与内容梗概;
三级阅读:阅读全文;

简单解释一下,就是我们需要将看似永远读不完的信息列表分为三级阅读,并通过 AI 来辅助我们创建介于“只看标题”和“阅读全文”之间的二级阅读。
一级阅读,只读标题。它可能是我们根本不关心的信息,或者是仅仅从标题就已经完成信息获取的信息。比如,一条纯粹的新闻(苹果宣布将于某月某日举办2023年的WWDC)。
二级阅读,只读摘要。它可能是一些我们关心但标题无法承载的信息,或者是标题关心但内容过长我们无法判断是否需要进一步阅读的信息。比如,看到一篇论文《当代中国青年群体耐人寻味的五重悖论》,我对这个话题很感兴趣,但这个话题实在太宏观了,它究竟是否在我关心的那个切入角度上回答问题,决定了我是否要阅读这篇论文的全文。而作为一篇社科论文,它足有 8500 字,并且没有典型的摘要(Abstract)和结论(Conclusion)这个部分。因此,我需要由 AI 帮我在这一等级生成一个内容概要和观点列表。在这里,我可以只读摘要,决定我是否要进行下一级阅读。
三级阅读,阅读全文。针对第二级过滤后的内容,我们会判断出是否需要阅读原始信息的全文。比如,对于一些论文,尽管我们在第二级阅读中已经了解了它的核心观点,但它的观点十分反直觉,我们需要看一下它的论证或实验过程。又或者是对于一些故事性的稿子,当我们看完第二级的故事梗概后,对故事仍未失去兴趣,也可以进入第三级进行全文阅读。并在第三级阅读中,可以适当的产生一些评论与批注,以备后续的检索与回顾。
比起直接在 RSS 阅读器里用 Edge 的边栏 New Bing 来生成文章摘要。这么做的好处,是你每次只需要打开一个列表,并采用一种阅读思路去处理列表,显著降低上下文切换时间。你不会因为在刷今日的 RSS 列表时因为点开一篇需要深度阅读的文章,而错过剩下的所有信息。你在一级阅读时,就专注看标题,在二级阅读时,就专注看摘要,三级阅读则是你的长期阅读库,在任何有整块时间的时候再打开它来慢慢细读。
说完了这个原理,再加上上文的流程图,其实你们已经可以自己去用自己趁手的工具搭建这个阅读 Workflow 了。
在我的设想中,应当出现这样一个 App,它类似于信息的 Tinder。允许你订阅成百上千的 RSS 信息源,然后在第一轮左滑右滑中仅展示标题。信息一旦右滑,则进入第二级生成文章摘要。在第二轮左滑右滑中,卡片展示标题与摘要,在第二轮右滑的信息,进入深度阅读列表,可以像普通的阅读器那样对长文章进行深度阅读。
但既然这个理想中的 App 目前还没有出现(我的建议是创业者也不要做,这看起来不是一个能自负盈亏的产品,它只能作为一个阅读器的功能,但不能彻底颠覆阅读器的一些底层功能)。那么是否能够利用现成的工具完成这样一个三级阅读 Workflow 呢?
Update: 在文章于博客首发后的几天,我发现了一款近似这样的产品,名为@会读ReadFlow 但刚上线功能较为简单,可以尝试。
答案是有的,并且你不需要任何 Code 工作,真的是无代码实现。

我们需要的工具是 Inoreader(或任意 RSS 阅读器)+ Notion 来实现。
首先,使用 Inoreader 来订阅你所有的内容源,如果你的信息源不支持 RSS,也可以通过 RSSHub 或 WeRss 等工具来为它生成一个 RSS。
第二步,在 Inoreader(或任意 RSS 阅读器)中完成一级阅读。也就是在 RSS 阅读器中完成标题阅读的工作,因为一般来说 RSS 阅读器都提供一个比较好的标题列表(相比 notion 的 database)。
第三步,在 Inoreader(或任意 RSS 阅读器)中筛选进入二级阅读的内容。目前,Inoreader 不支持直接将内容分享到 notion,你可以借助 make.com 或 Zapier 这样的工具,建立一个“自动化”过程。比如, 在 Inoreader 中星标文章,则自动将文章保存到 notion 的某一个 Database。

第四步,通过 notion 的“AI Auto-fill”功能来让 AI 生成每篇入库文章的摘要与关键要点。
这里多说一点,AI Auto-fill 是 notion 在近期上线的新功能,它支持在一个 database 中建立一个 Property,这个 Property 会在你新添一条记录时,自动按照你的要求生成一个字段的内容。notion 默认提供了 AI key info(以列表形式呈现关键信息)和 AI Summary(以自然语言形式提供一个内容总结)两个选项,但你也可以选择 AI custom autofill 来填入你自己的 prompt,比如你甚至可以让它根据文章自动为你进行分类和打标签。

第五步,在 notion 中阅读由 AI 生成的文章总结与核心观点,判断文章是否需要进入下一步的全文阅读。这里,你需要再建一个 Property 来帮助筛选文章状态。比如我的“文章状态”有三级阅读、已读完。
同时,建立两个 View,分别用 filter 对“文章状态”进行筛选,分别对应文章处在二级阅读、三级阅读还是已读完的状态。
这里我的图片有点错误,因为已经在 RSS 阅读器中完成了一级阅读(一级阅读的文章不会进入 notion),因此在 notion 中实际不需要考虑一级阅读的部分。你也不需要在“文章状态”中设置二级阅读标签,因为进入 notion 库的都是二级阅读,只需要“三级阅读”和“已读完”标签就行。
至此,一个完全基于现有图形化工具的三级阅读流就已经完成啦,中间的每个过程你都可以替换。比如,如果你没有 Inoreader 的高级会员,那么可以用 notion-feed 这个工具,直接将 RSS 订阅进 Notion,然后通过增加一个 view 来在 notion 界面里完成一级阅读。
如果你的主要信息流并不来自 RSS,也可以像我一样,通过简悦插件将任何网页以全文形式存入 notion。当然,如果你不用 notion,或者不愿意订阅 notion AI,那你也完全可以通过 OpenAI 的 API 来实现以上的阅读流,但那就需要你拥有一些代码技能了。
不过,根据我的推算,通过 OpenIAI 的 API 来筛选个人信息流可能不是一个划算的选项,因为所有的内容都要过一遍 API,哪怕是用 GPT-3.5,价格也不算低。
不过,如果谁愿意做个开源的信息 Tinder 项目就更好啦。


评论
《 “基于 RSS 和 notion AI 打造三级信息阅读 Workflow” 》 有 5 条评论
你这真是硬核阅读爱好者。
readwise reader可以实现你的需求
离不开 innoreader,不想再付一份 rss 阅读器的钱了…
[…] 我去年曾在《基于 RSS 和 notion AI 打造三级信息阅读 Workflow》里介绍过以 notion 为核心打造阅读库,其中也涉及到了 notion AI 的使用。但其实在这个文章中我没有说的是,我一直在用 Cubox Pro 做 Notion 的前端剪藏器——因为 notion 的剪藏插件太烂了,对大部分国内的网站或文章都只能存一个标题。 […]
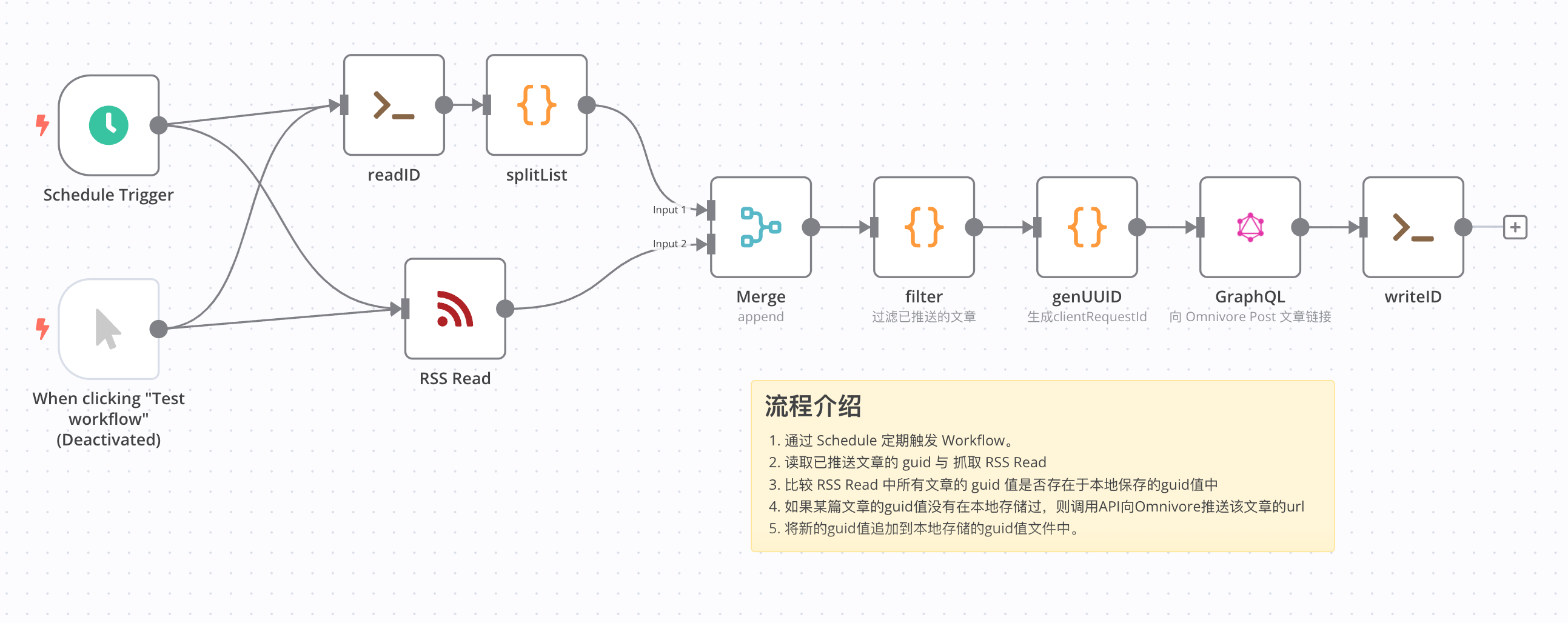
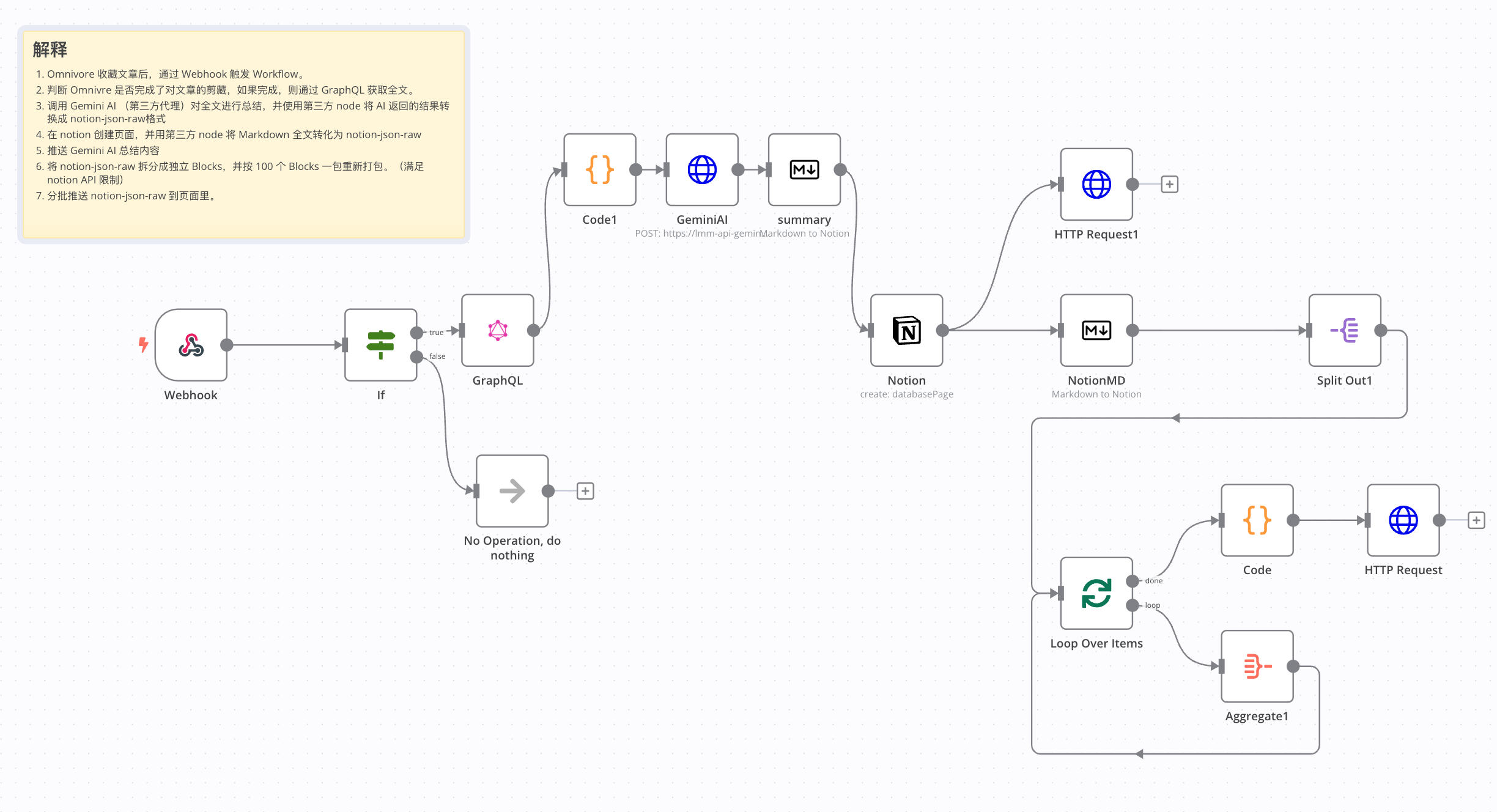
感谢分享,我参考你的流程用n8n做了一套三级阅读的方案,FreshRss (定时抓取FreshRss中某个标签下的文章)——> Omnivore(使用Gemini AI总结内容) ——> Notion